YOLOv1
YOLO(v1):Redmon J, Divvala S, Girshick R, et al. You Only Look Once: Unified, Real-Time Object Detection[J]. 2015.
1.网络结构
这个YOLO的原始基本上结构是基于GoogLeNet,不同的是,YOLO未使用inception module,而是使用1x1卷积层(此处1x1卷积层的存在是为了跨通道信息整合)+3x3卷积层简单替代。经过卷积和两层全连接后输出shape为7730,SS(B*5+C),S是分为多少个格子,B是每个点负责预测多少个box,C为分类数,这里是20.两层全连接的原因是理论上两层足矣拟合任何非线性函数。
2.优缺点分析
2.1检测速度快
YOLO将目标检测重建为单一回归问题,对输入图像直接处理,同时输出边界框坐标和分类概率,而且每张图像只预测98个bbox,检测速度非常快,在Titan X 的 GPU 上能达到45 FPS,Fast YOLO检测速度可以达到155 FPS。
2.2背景误判少
以往基于滑窗或候选区域提取的目标检测算法,只能看到图像的局部信息,会出现把背景当前景的问题。而YOLO在回归之前做了全连接,在训练和测试时每个cell都使用全局信息做预测,因此不容易把背景误认为目标。
2.3泛化性更好
YOLO能够学习到目标的泛化表示,能够迁移到其它领域。例如,当YOLO在自然图像上做训练,在艺术品上做测试时,YOLO的性能远优于DPM、R-CNN等。
2.4对比FR-CNN
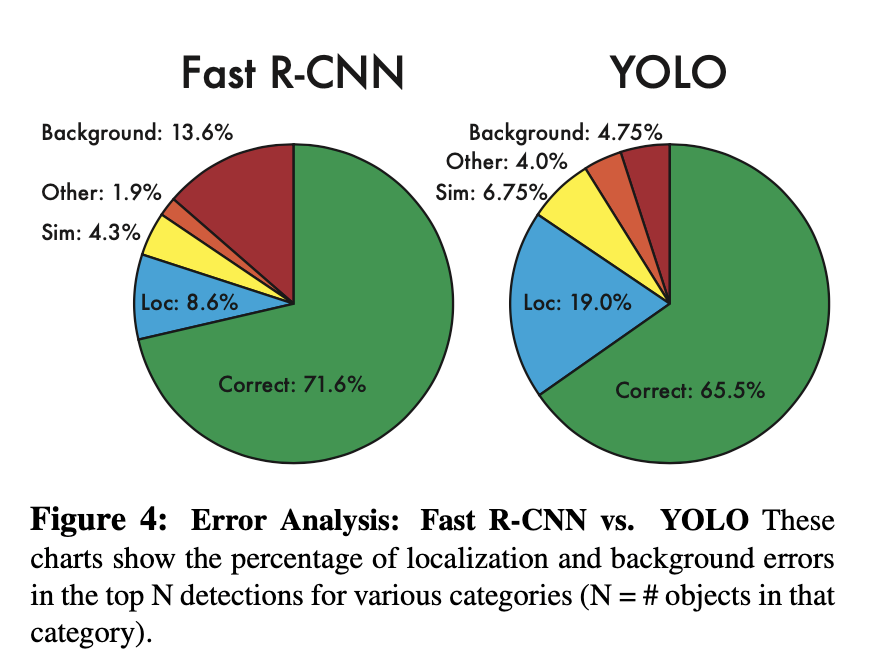
这里我们来对比一下FastR-CNN 和YOLO的错误分析图,刚才分析到yolo的一个优点是背景误判少,从图中看YOLO的背景误检率为4.75%,FastR-CNN为13.6%,确实要低一些。 其中,正确分类是指类别分类正确,交并比大于0.5, 定位错误是指类别分类正确,交并比在0.1-0.5区间内, 分类相似是指类别相近,交并比>0.1 背景误判为交并比小于0.1的任何目标, 其他为分类错误的交并比高于0.1的目标。
还有一个明显的地方就是YOLO的定位错误要比Fast R-CNN高很多,甚至比YOLO其他错误加起来还要多。下面我们就来分析一下YOLO的问题。 (这个问题主要是因为YOLO的loss函数)
2.5邻近物体检测精度低
YOLO对每个cell只预测两个bbox和一个分类,如果多个物体的中心都在同一cell内,检测精度低。
2.6损失函数的设计过于简单
损失函数包含了坐标误差、IOU误差、分类误差 对于坐标和分类都同时用了MSE这个损失,因为这是两类不同的问题,一个是框在哪儿,一个是框里到底什么物体,都是把它强行的放在一起都用MSE去处理,这个有点太暴力。
2.7 训练不易收敛
因为它直接预测BoundingBox的位置,相对与预测物体的偏移量,模型不太好收敛。总的来说就是快速粗暴.
Yolov2
YOLO(v2):Redmon J, Farhadi A. YOLO9000: better, faster, stronger[C].2016
1.主要思想
YOLOv2相对v1版本,在继续保持处理速度的基础上,从预测更准确(Better),速度更快(Faster),识别对象更多(Stronger)这三个方面进行了改进。其中识别更多对象也就是扩展到能够检测9000种不同对象,称之为YOLO9000。

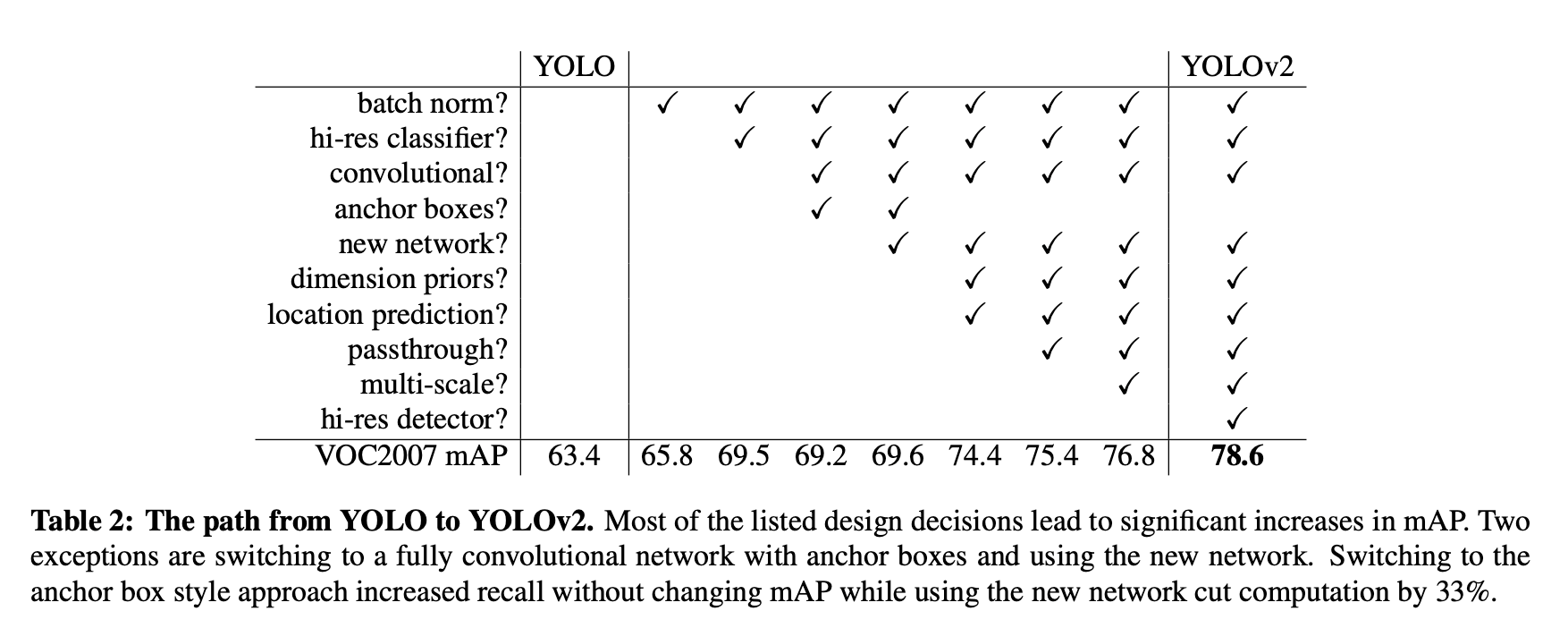
2.The path from Yolo to Yolov2
2.1批归一化
作者首先尝试了批归一化,这个大家应该比较熟悉了,主要目的是保持深度神经网络在训练过程中保持每一层的神经网络输入都是保持相同分布,这样的效果是可以加快模型收敛。随着网络深度加深或者在训练过程中,隐藏层的输入分布逐渐发生偏移或者变动,由于整体分布逐渐往非线性函数的取值区间的上下限两端靠近,比如sigmoid来说,反向传播容易造成梯度消失,将分布拉回到0-1区间,使梯度变大利于收敛。 batch norm的作用一句话概括就是,对于每个隐层神经元,把逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。
2.2使用高分辨率图像微调分类模型
当时用于目标检测算法的训练数据较少,通常在ImageNet分类数据集上进行预训练特征提取模型,输入数据大多为224224,但是检测的数据通常是较高分辨率的,作者在新的YOLO网络把在分类中加入了448448的finetune。
2.3 去掉全连接层并采用先验框
之前的YOLO利用全连接层的数据完成边框的预测,导致丢失较多的空间信息,定位不准。作者在这一版本中借鉴了Faster R-CNN中的anchor思想。
2.4 Darknet19&passthrough
 这里我们结合Darknet19的网络模型图,再来理解一下前面叙述的那么多繁琐的trick。作者在YOLOv2中使用了一个新的分类网络作为特征提取部分,参考了一些前人的经验,使用了较多的3 * 3卷积核,在每一次池化操作后把通道数翻倍。借鉴了network in network的思想,网络使用了全局平均池化(global average pooling),把1 * 1的卷积核置于3 * 3的卷积核之间,用来压缩特征。也用了batch normalization(前面介绍过)稳定模型训练。
这里我们结合Darknet19的网络模型图,再来理解一下前面叙述的那么多繁琐的trick。作者在YOLOv2中使用了一个新的分类网络作为特征提取部分,参考了一些前人的经验,使用了较多的3 * 3卷积核,在每一次池化操作后把通道数翻倍。借鉴了network in network的思想,网络使用了全局平均池化(global average pooling),把1 * 1的卷积核置于3 * 3的卷积核之间,用来压缩特征。也用了batch normalization(前面介绍过)稳定模型训练。
作者使用Darknet在ImageNet的1000类分类数据集上训练了160次,然后把分辨率上调到了448448,然后又训练了10次,这样的目的是为了适应检测样本的高分辨率。 分割线上面的是用于分类的网络结构,用于检测的网络需要把下面最后一层卷积平均池化和softmax去掉,换成下面的图的形式,加入三个331024的卷积,一个passthrough层,最后用一个11的卷积输出预测结果,输出的channels数为:num_anchors*(5+num_classes)。
这里passthoru的作用是增加小粒度特征,具体做法是将第一个五连卷积输出的结果,在检测时size为2626512,用11卷积降维为262664,再一拆成四为1313256,然后和最后一层卷积相加。13131024+1313256经过11卷积最后输出1313125。
2.5 维度聚类
作者在使用anchor box的时候遇到了两个问题。 第一个是anchor boxes的宽高维度往往是精选的先验框(hand-picked priors),虽说在训练过程中网络也会学习调整boxes的宽高维度,最终得到准确的bounding boxes。但是,如果一开始就选择了更好的、更有代表性的先验boxes维度,那么网络就更容易学到准确的预测位置。于是作者尝试使用K-means聚类方法训练bounding box,并且在实验中发现传统的欧式距离函数在聚类中效果并不好,较大的boxes会比较小的boxes产生更多的error,聚类结果可能因此偏离,所以加入了IOU得分作为距离衡量函数。在k=5的时候召回率和复杂度比较平衡。
2.6 直接位置预测
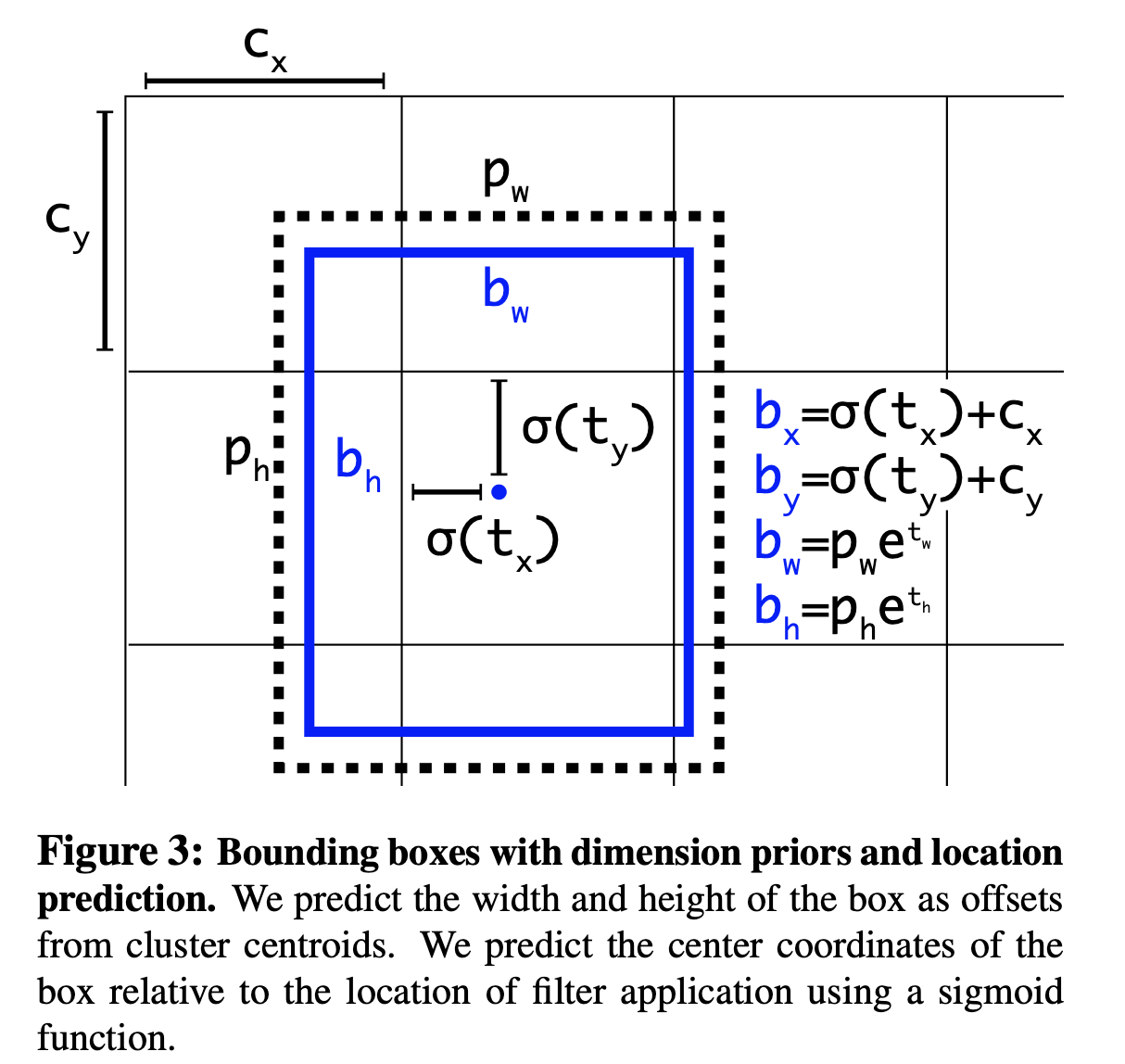 另一个问题就是模型早期迭代时不够稳定,这是由于预测box时位置时的公式限制不够。
左面的就是初始使用的预测box位置公式,这里应该是+号,论文作者应该是笔误,Xa,Ya是框的初始位置,wa和ha是宽和高,tx和ty是网络预测出的参数,这个公式没有加以限制条件,所以任何anchor box都可以偏移到图像任意的位置上。随机初始化模型会需要很长一段时间才能稳定产生可靠的offsets(偏移量)。
YOLO这里的做法是不预测x,y的偏移量,直接预测位置,tx,ty,tw,th由网络预测得出。
σ(tx)函数将预测值限定到了0-1之间.这样就保证了我们预测出来的box仍然是围绕着当前cell的.这一点也使得网络更稳定.
另一个问题就是模型早期迭代时不够稳定,这是由于预测box时位置时的公式限制不够。
左面的就是初始使用的预测box位置公式,这里应该是+号,论文作者应该是笔误,Xa,Ya是框的初始位置,wa和ha是宽和高,tx和ty是网络预测出的参数,这个公式没有加以限制条件,所以任何anchor box都可以偏移到图像任意的位置上。随机初始化模型会需要很长一段时间才能稳定产生可靠的offsets(偏移量)。
YOLO这里的做法是不预测x,y的偏移量,直接预测位置,tx,ty,tw,th由网络预测得出。
σ(tx)函数将预测值限定到了0-1之间.这样就保证了我们预测出来的box仍然是围绕着当前cell的.这一点也使得网络更稳定.
2.7 YOLO9000
YOLO2在更快更准上已经取得了很好的效果,但是还有一个问题,VOC数据集只可以检测20种对象,但实际上对象的种类非常多,就像图中左图,奥巴马被识别为leader,他的夫人识别为American,右图中的各式各样的食物。YOLO2尝试利用ImageNet中大量的分类样本,联合COCO的对象检测数据集一起训练, 使YOLO2即使没有学过很多对象的检测样本,也能检测出这些对象。
实现9000种目标的检测需要一个关键的结构WordTree,ImageNet中大量的分类样本并没有手工标注的检测数据,YOLO9000的思路是如果是检测样本,训练时其Loss包括分类误差和定位误差,如果是分类样本,则Loss只包括分类误差。这样的话我们是不是只需要输出13135(5+9000)的一个softmax就可以简单分类? 这里有一个问题就是9000多个类别中并不全是互斥的,比如刚才的例子中animal和dog是包含的关系。那么softmax最后只取一类显然是不正确的,为了解决这个问题我们可以引入WordTree结构,同一层的类别都是互斥的,父子关系表示包含。这样在分类的时候我们可以使用多组softamx,分类为当前节点为这条路径的条件概率。yolo9000的输出为13133(4+1+9418)
3. Yolo2 优缺点分析
3.1 优点
- 快速,pipeline简单。
- 背景误检率低。
- 通用性强,对于非自然图像物体检测效率远高于RCNN系列。
3.2缺点
- 小目标检测效果较差
- 检测精度还不够高
Yolov3
YOLOv3:Redmon J, Farhadi A. Yolov3: An incremental improvement[J]. 2018.
2013年,R-CNN横空出世,目标检测DL世代大幕拉开。
各路豪杰快速迭代,陆续有了SPP,fast,faster版本,至R-FCN,速度与精度齐飞,区域推荐类网络大放异彩。(2014-2016)
奈何,未达实时检测之基准,难获工业应用之青睐。
此时,凭速度之长,网格类检测异军突起,先有YOLO,继而SSD,更是摘实时检测之桂冠,与区域推荐类二分天下。然准确率却时遭世人诟病。(2016)
遂有JR一鼓作气,并coco,推v2,增加输出类别,成就9000。此后一年,作者隐遁江湖,逍遥twitter。偶获灵感,终推v3,横扫武林!(2017、2018)
改进点
1.多尺度预测
通过聚类得到三种不同size的anchor box,每种有三种不同形状,共九种。 1313 2626 52*52不同大小的特征分别对应不同大小的目标。
2. 分类器-类别预测
不使用softmax,使用独立的多个logistic分类器替代。
3.基础特征提取网络Darknet53
Darknet53的网络结构,可以数一下一共包括53个卷积层,所以得名Darknet53,和Darknet19类似,都包括很多11 和33的卷积,不同是加深了网络层数,以及新增的残差单元。检测部分分别取了1313 2626 52*52三种尺度的特征图,分别进行上采样融合,配合不同尺度的初始anchor box 组成检测部分,可以预见的是这样的结构会极大提升网络对小目标检测的效果。
End
自此Yolo系列正式告一段落,JR在个人Twitter上宣布,将停止一切CV研究,原因是自己的开源算法已经用在军事和隐私问题上。这对他的道德造成了巨大的考验。后续的v4由他的实验室同僚发布,进行了一系列改进,效率和准确率进一步提升,更进一步的yolov5在不久后发布,但是只是开源了代码仓库,没有发表文章。
拓展
- YOLO-v4 :Bochkovskiy A, Wang C Y, Liao H Y M. Yolov4: Optimal speed and accuracy of object detection[J]. arXiv preprint arXiv:2004.10934, 2020
马赛克数据增强;SPP模块;FPN+PAN结构;cmBN;SAT自对抗训练;CSPDarknet53;MISH激活;CIOU_loss;DIOU_nms
- YOLO-v5 :https://github.com/ultralytics/yolov5
自适应锚框计算;Fcous结构;GIOU_loss